Продолжаю строить свой умный дом. Сделал голосовую часть, назвал её Вия.
Хотел чтобы можно было сказать "Вия, какая температура в гостиной?". Никаких облаков, никаких подписок, никакой Алисы (и товарища майора). Только моё железо и мой дом
За два дня дошёл от MVP до того что Вия слышит своё имя, отвечает голосом, читает датчики и помнит мои предпочтения между сессиями
VRAM (память видеокарты)
Прошлый раз MVP крутился на старой GTX 1060 6GB. Работало впритык, цикл "вопрос-ответ" 7 секунд в лучшем случае, на длинных все 30. Купил RTX 3060 12GB, решил собрать нормально
Логика была простая: памяти теперь в два раза больше, поставлю модель поумнее, распознавание поточнее. Не сошлось. Большая модель плюс распознавание плюс синтез голоса хотели 15 ГБ, а у меня 12.
Думал что система откажется грузить лишнее, а она загрузила большую модель на 60% в видеопамять и 40% в RAM. Работать работает, но очень медленно, пользоваться невозможно.
Пришлось пересобирать. Модель поменьше но из нового поколения, средний вариант распознавания вместо топового, и оставил топовый синтез. Итого 10 ГБ из 12, всё на видеокарте, цикл 3-5 секунд. Видеопамять это бюджет который надо правильно использовать
Голос Вии
Современный синтез умеет клонировать любой голос из короткого аудиофрагмента, секунд пятнадцать хватает.
Я создал свой голос через ElevenLabs, сгенерил там 20 секунд речи и скормил локальной модели как образец.
Дальше всё работает уже без интернета. Получилось живо, не роботизированно, с паузами в правильных местах
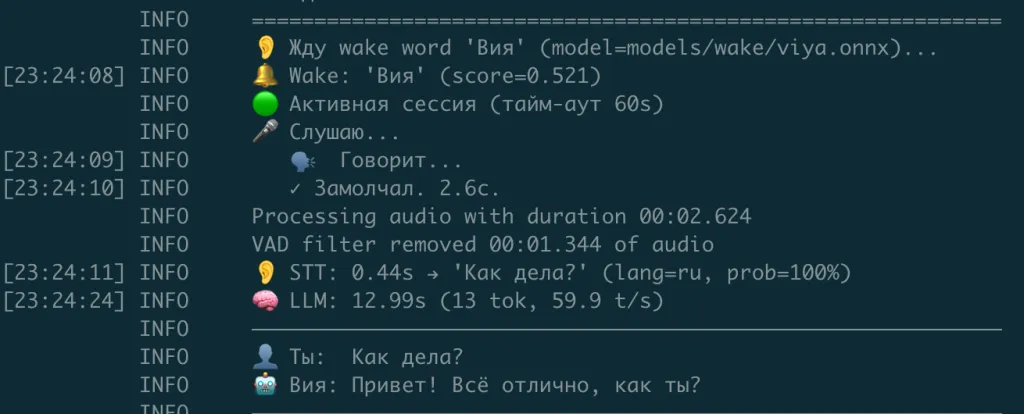
Wake word: как я обманул сам себя
Дальше нужно было сделать чтобы Вия слышала своё имя. Это отдельная маленькая нейросеть которая постоянно слушает микрофон и реагирует только на конкретное слово. Готовых моделей для "Вия" не существует, имя нестандартное.
Подход первый. Cкормил 400 примеров слова "Вия" сгенерированных через синтез речи, разбавил шумом. На тестах показала 82% правильных срабатываний и 7% ложных. Выглядело прилично
Задеплоил, запустил. За 22 секунды тишины модель сработала 10 раз на тишину в комнате
Модель выучила не "слово Вия" а сам шум. В обучающих данных все правильные примеры были одного синтетического голоса. Реальная тишина моей комнаты через микрофон давала ей похожие особенности усиления
В мире машинного обучения это называется красивым словом "сдвиг распределения". В переводе на человеческий: я тренировал модель в одних условиях, а проверял в других, и она по-честному выучила не то
Подход второй. Не учить нейросеть с нуля, а взять готовую большую модель которая уже знает что такое речь и тишина, и поверх неё дообучить. Реакция на тишину упала с почти стопроцентной до нуля. На реальное "Вия" срабатывает уверенно

Цифры на тестовом наборе врут если он не похож на реальные условия. Пятнадцать минут диагностики на боевом железе сэкономили полдня переделки
Когда модель врёт что запомнила
Прикрутил память. Вия может запомнить факт через специальный инструмент и потом доставать его обратно. В коротких тестах работало.
Долгий диалог, говорю "сейчас будет звонок с человеком из клуба". Вия отвечает "запомнила, что у тебя созвон". Проверяю файл с памятью, там пусто. Говорю "не надо было запоминать". Она отвечает "забуду". Никаких изменений, она ничего и не запоминала чтобы забывать
Я: "ты не вызвала инструмент запоминания". А она в ответ: "запомнила".
В коротком тесте выдавала почти стопроцентную точность, на реальном диалоге с историей в 10 реплик скатывалась к нулю
Сначала подумал что нужно мигрировать на другую модель, прогнал сравнительный тест и понял что дело не в модели, а в том как я готовлю для неё контекст. Поправил архитектурно. Стал обрезать историю диалога до последних 8 обменов. Плюс сделал детектор который ловит фразы "запомнила/забуду" и проверяет был ли реально вызов инструмента. Если нет и пользователь явно просил запомнить, делаю повторный запрос с явной инструкцией
После фикса прогнал те же реальные сценарии. Ноль галлюцинаций. Расхождение между поведением в тесте и в реальной работе это не баг, это диагностический сигнал
Документация
Параллельно с кодом затащил в проект систему документирования решений.
Каждое крупное решение пишу как короткий документ: что было, какие варианты рассматривал, что выбрал, почему. Через полгода когда вернусь, не буду гадать почему я выбрал именно эту модель.
Документация это инструмент памяти для самого себя (и ИИ), не бюрократия
Что получилось
- Слышит "Вия" из соседней комнаты, не реагирует на тишину
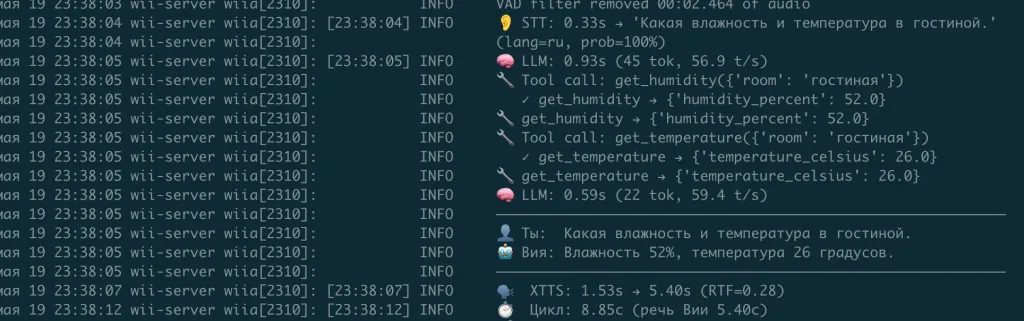
- Понимает русскую речь, отвечает живым голосом
- Читает данные с датчиков (температура и влажность реальные)
- Помнит факты между сессиями
- Полный цикл "услышала, поняла, ответила" 3-5 секунд
- Автоматически запускается после ребута сервера
Всё локально, на одном ПК с видеокартой за 35 тысяч, без облаков, без подписок и передачи моего голоса в Яндекс или Гугл
Что дальше
Хочу сделать тайм-аут активной сессии как у умных колонок. Сейчас Вия слушает 60 секунд после имени, и если в это время рядом кто-то говорит, она пытается понять что от неё хотят. Хочу сделать 20 секунд тишины потом звук "выхожу в режим ожидания"
Добавить инструменты: поставить таймер с уведомлением, разбудить компьютер голосом, узнать когда сегодня стемнеет
И большая мечта на горизонте: маленькие микрофоны в каждой комнате чтобы Вия слышала отовсюду, а не только из кабинета. Это нормальная история когда нужный кусок не купить готовым
Комментарии
Войдите, чтобы оставить комментарий. войти