
Вторая статья из серии «Соло-разработка с AI-агентами»
В первой я рассказал про путь от Tabnine до Claude и первый оркестратор. Сегодня - про фундамент, без которого агенты превращают кодовую базу в кашу.
Проблема: агент без контекста
Когда я впервые запустил Claude Code на проекте, он написал рабочий код. Технически корректный. И абсолютно не вписывающийся в проект.
Он не знал, что у меня Hexagonal Architecture на бэкенде. Не знал, что em-dash запрещён во всех файлах проекта. Не знал, что vendor/ нельзя трогать (привет, Minimax из первой статьи). Не знал, что есть два террейна в Unity-сцене и что деплой идёт через конкретный скрипт.
Агент - это сильный разработчик с полной амнезией. Каждую сессию он начинает с нуля. И если ты не скажешь ему правила - он придумает свои.
Решение оказалось одним файлом в корне проекта.
Что такое CLAUDE.md
CLAUDE.md - файл в корне репозитория, который Claude Code автоматически читает при запуске сессии. Это не документация для людей. Это инструкция для агента: что можно, что нельзя, как устроен проект, где искать контекст.
Можно думать о нём как о должностной инструкции для нового сотрудника, который каждое утро забывает всё что было вчера. Звучит абсурдно - но именно так работают языковые модели. И именно поэтому этот файл важнее любого промпта.
Промпт - это разовая задача. CLAUDE.md - это постоянные правила игры.
Три проекта, три CLAUDE.md
У меня три активных проекта на разных стеках. В каждом свой CLAUDE.md, и каждый устроен по-разному - потому что проекты на разных стадиях и разной сложности.
Exorim (MMO-игра) - самый зрелый
Exorim - это Unity + Colyseus + Laravel + Nuxt. Четыре компонента, монорепо. CLAUDE.md здесь прошёл несколько итераций: начинался как простой файл на пару килобайт, вырос до 22KB, потом я разделил его.
Сейчас в корне ~12KB - общие правила. А каждый компонент (game-server, game-client, web-backend, web-frontend) имеет свой вложенный CLAUDE.md с локальной спецификой. Когда запускаешь сессию Claude Code внутри конкретной директории компонента - он читает и корневой, и локальный файл.
Что в корневом файле Exorim:
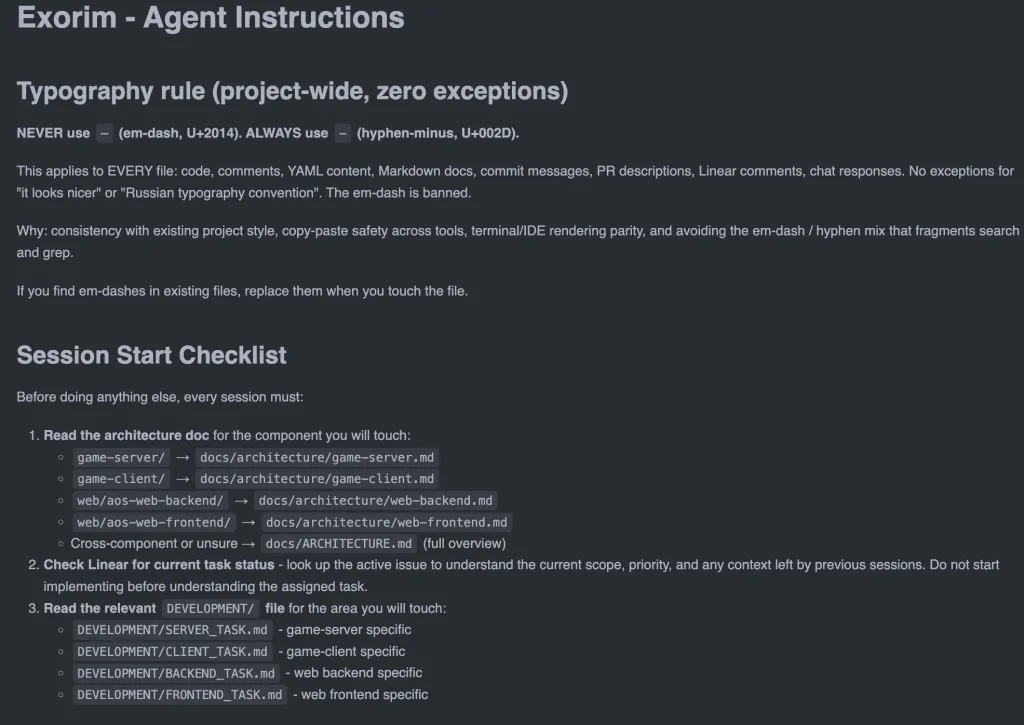
Типографское правило - первое что видит агент. Em-dash (длинное тире) запрещён во всём проекте. Звучит мелочно, но после того как агент трижды вставил em-dash в YAML-конфиг и сломал парсинг - я записал это правило первой строкой. Если находит em-dash в существующих файлах - заменяет при касании.
Session Start Checklist - перед любой работой агент обязан: прочитать архитектурный документ компонента, проверить текущую задачу в Linear, прочитать файл DEVELOPMENT/ с логами предыдущих сессий. Без этого он начинает работу вслепую.
Post-Task обязанности - после завершения задачи агент обязан обновить архитектурную документацию и записать лог в DEVELOPMENT/*.md. Это критично: если агент поменял схему MongoDB или добавил новый сервис, а следующая сессия об этом не знает - будет конфликт.
Off-Limits директории - список папок, которые агент не должен трогать. misc/, 3d/, NFT/, ton/. Без этого агент при поиске по проекту залезет куда не нужно и начнёт "помогать" в областях, которые не в его компетенции.
Quick Reference - таблица компонентов со стеком и путями. Агент сразу видит: game-server это Node.js + Colyseus + MongoDB, а не Django + PostgreSQL.
ProVybor (B2B-маркетплейс) - самый компактный
ProVybor - это Laravel + Nuxt, два репозитория. CLAUDE.md здесь минимальный - 30 строк. И это осознанный выбор, не лень.
Что в нём: описание продукта в одном абзаце, ссылки на два репозитория (у каждого свой вложенный CLAUDE.md), обязательное чтение перед работой (DECISIONS.md, WEEKLY_LOG.md), трекер задач (YouTrack, а не Linear - у каждого проекта свой трекер), и текущий главный блокер.
Отдельная фишка - папка everyday-tasks/ с гранулярными выжимками по завершённым задачам. Каждый файл - один день, один слаг. Агент перед планированием новой задачи сканирует индекс, чтобы не повторять уже принятые решения.
Почему так коротко? Потому что ProVybor - типовой веб-проект. Laravel + Nuxt, гексагональная архитектура - агент с этим стеком справляется без длинных инструкций. Правила на уровне компонентов живут во вложенных CLAUDE.md.
WII Home (умный дом) - самый подробный
WII Home - это TypeScript на Raspberry Pi + Python на сервере с RTX 3060 + MQTT + голосовой ассистент. Здесь CLAUDE.md самый большой, потому что стек нестандартный и агент без подробного контекста не поймёт, как всё связано.
Что уникального:
ASCII-топология сети - прямо в CLAUDE.md нарисована схема: какие устройства, на каких IP, что с чем связано через MQTT. Агент видит это при старте и понимает физическую архитектуру.
Три вида памяти - и это не шутка. Первая: память самого агента (правила работы). Вторая: память голосового ассистента Вии (файл на сервере, туда пишет только Вия через tool_call, агент не трогает). Третья: docs/memories/ в Obsidian vault - кураторская версия фактов, которую пишет агент когда узнаёт новое. Без явного разделения агент начнёт писать в чужую память и сломает ассистента.
Автодеплой - в отличие от Exorim, где деплой ручной, WII Home агент деплоит сам после git push. Но с нюансами: только финальный коммит задачи (не каждый промежуточный), показывает ключевые строки вывода, при merge conflicts - стоп.
Специфика железа - в CLAUDE.md прописано, что RPi build через SSH требует source ~/.nvm/nvm.sh перед любой npm-командой, потому что неинтерактивная SSH-сессия агента не наследует окружение NVM. Такие вещи невозможно знать заранее - они появляются после первого бага.
Общие паттерны: что должно быть в любом CLAUDE.md
После трёх проектов я вижу четыре обязательных блока:
1. Запреты - что агент не должен делать. Директории, команды, файлы. Это самый важный блок, потому что агент по умолчанию считает что ему можно всё. Если не сказать «не трогай vendor/» - он туда полезет. Если не сказать «не делай migrate:fresh» - он сделает.
2. Контекст проекта - стек, архитектура, где что лежит. Таблица или краткое описание. Агент не должен угадывать.
3. Обязательное чтение - ссылки на документы, которые агент должен прочитать перед началом работы. Архитектура, decision log, текущие задачи. Без этого он начинает с нуля.
4. Вложенные CLAUDE.md - если проект больше одного компонента, общий файл в корне + специфичные файлы в подпапках. При запуске сессии из директории компонента Claude Code читает оба: корневой и локальный.
Чего в CLAUDE.md быть не должно: полная документация по каждой фиче, TODO-листы, история изменений, тексты промптов. Если раздел нужен в 1 из 10 задач - выноси в docs/.
Obsidian: долгосрочная память, которой нет у агента
CLAUDE.md решает проблему контекста внутри сессии. Но у агента есть вторая проблема - он не помнит что было вчера. Каждая новая сессия Claude Code начинается с чистого листа.
Obsidian vault решает это.
Как это устроено
В каждом проекте есть папка docs/, которая одновременно является Obsidian vault. Я вижу её в Obsidian как wiki с навигацией и поиском. Агент видит те же файлы через файловую систему или MCP-сервер.
Связка работает через симлинки: docs/ в репозитории - это симлинк на vault в Obsidian. Когда агент пишет лог в docs/DEVELOPMENT/SERVER_TASK.md - я вижу обновление в Obsidian в реальном времени. Когда я пишу архитектурную заметку в Obsidian - агент видит её при следующем запуске.
Что живёт в vault
DEVELOPMENT/*.md - операционные логи. Агент после каждой задачи дописывает (не перезаписывает!) что было сделано, какие файлы изменены, какие ограничения остались. Следующая сессия читает этот файл и понимает контекст.
DECISIONS.md - decision log. Каждое архитектурное решение пронумеровано, с датой и обоснованием. В Exorim их 11+ штук. Агент читает их перед работой и не переизобретает уже принятые решения.
architecture/*.md - документация по компонентам. Обновляется агентом после каждого изменения архитектуры (это прописано в CLAUDE.md как обязанность).
В WII Home дополнительно:
decisions/- ADR в формате дата-slug (хронологически)memories/- кураторские заметки о предпочтениях пользователяdevices/- документация по каждому устройствуplaybooks/- инструкции "как сделать X"
MCP-сервер: когда файловой системы мало
В WII Home я пошёл дальше и настроил MCPVault - MCP-сервер для Obsidian. Агент получает инструменты: поиск по заметкам (BM25), чтение, создание, точечная правка без перезаписи, управление тегами и фронтматтером.
Зачем это нужно если агент и так видит файлы? Потому что BM25-поиск быстрее чем grep по 200 файлам, и потому что patch_note делает точечную правку без риска перезаписать весь файл (а это реальная проблема - стандартная запись через mcp-obsidian перезаписывает файл целиком).
Нужен ли MCP-сервер всем? Нет. В Exorim и ProVybor его нет - хватает обычного чтения файлов. MCPVault имеет смысл когда vault вырастает до 100+ заметок и обычный поиск становится медленным.
Почему не RAG
Честно - у меня нет опыта с RAG, и пока не было потребности пробовать. CLAUDE.md + Obsidian + файловая система закрывают мои задачи. Агент сам ходит по файлам, контекстного окна Claude хватает чтобы вместить архитектурный документ + текущую задачу + историю сессий. Если упрусь в потолок - посмотрю в сторону RAG. Пока не упёрся.
Эволюция: от одного файла к системе
Мой CLAUDE.md прошёл три стадии:
Стадия 1: один файл, пара килобайт. Описание стека, пара запретов. Работает первую неделю, потом агент начинает делать ошибки которые ты уже объяснял.
Стадия 2: один файл, 22KB. Всё в одном месте. Работает, но агент тратит токены на парсинг разделов, которые не относятся к текущей задаче. ~20K токенов на старте, ~10% контекстного окна только на инструкции.
Стадия 3: корневой файл + вложенные + docs/. Корневой ~12KB - общие правила. Вложенные CLAUDE.md по компонентам - читаются при запуске сессии из соответствующей директории. Справочники в docs/ - читаются по запросу. Агент получает только релевантный контекст.
Переход между стадиями каждый раз был вызван конкретной болью, не желанием "сделать красиво".
Практические советы
Если вы только начинаете работать с Claude Code:
Начните с запретов. Первое что добавьте - список того, чего агент делать не должен. Деструктивные команды, директории вне скоупа, форматы которые не используете.
Добавляйте правила после багов. Каждый раз когда агент делает ошибку - спросите себя: «Могу ли я предотвратить это правилом в CLAUDE.md?». Em-dash ban, NVM-хак для RPi, запрет на перезапись логов - всё это появилось после реальных проблем.
Не пишите документацию для людей. CLAUDE.md - это инструкция для модели. Модели не нужны вступления, мотивация и контекст "почему это важно". Ей нужны правила: делай так, не делай так, читай это перед работой.
Ведите decision log с первого дня. Агент, который знает почему вы выбрали MongoDB вместо PostgreSQL для game-server, не будет предлагать миграцию на PostgreSQL в каждом втором промпте.
Принцип 8-из-10. Если раздел нужен агенту в 8 из 10 задач - держите в корневом CLAUDE.md. Если в 1 из 10 - выносите в docs/. Корневой файл не должен расти бесконечно.
Что дальше
CLAUDE.md и Obsidian - это фундамент. Но фундамент бесполезен если на нём неправильно строить. Агент с идеальным контекстом всё ещё может написать 500 строк мимо, если промпт был нечётким. Или пропустить баг, если ревью диффа поверхностное.
В следующей статье - про промпт-цикл: как формулировать задачи для агента, как ревьюить результат, и где агент стабильно проваливается (с конкретными примерами из боевых проектов).
Серия «Соло-разработка с AI-агентами». Подписывайтесь на блог в Telegram, чтобы не пропустить.
Комментарии
Войдите, чтобы оставить комментарий. войти